<html>
⠀⠀<head>quote</head>
⠀⠀<body>
⠀⠀⠀<p>
⠀⠀⠀⠀⠀If the viewer turns his attention
⠀⠀⠀⠀⠀to the question of how the effects are made,
⠀⠀⠀⠀⠀he looks directly at
⠀⠀⠀⠀⠀the materiality of the medium itself
⠀⠀⠀</p>
⠀⠀⠀<!-- translated -->
⠀⠀⠀<a href="materialitaet.html">Hans Dieter Huber</a>
⠀⠀</body>
</html>|
.+:::::::::::::::::::::::::::::::::::::::::/
.//`+++++++++++++++++++++++++++++++++++++// s
-+/.h+..................................-os s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h/ ss s
-+/.h+ ss s
-++-yo////////////////////////////////////y`s
-+o-:--------------------------::::-:://:---s
-+/ :-.: +:oo- s
-+/```````````````````````````````````:-````s
./o//////////+o:::::::::::::::::s+/////////::
``://////////+s:::::::::::::::::y+/////////:.
s .::::/osso::::. .+
`.y +yyyyhNNNmyyyy+ .+
`:h:::::/+:::::::::::::+:///////////////////+--------------------
.o s s::::::::::::s.+ - +
-/y .o s ::::::::::::oss+::.+
`-y .o y `+//: .+
`.+/y/::/+:::::::::::::+:::::::::::::::::++:.
`////////////////////////////////////:/.
GET / HTTP/1.1 --------------------------------------------------------------------------------------->
Host: wwwwwww.jodi.org
Connection: close
Host: wwwwwww.jodi.org
Connection: close
<-------------------------------------------------------------------------------------- HTTP/1.1 200 OK
Server: Apache/2
Content-Type: text/html
Server: Apache/2
Content-Type: text/html
######## ## ## ## ## ## ## ######## ######## ### ######## #### ## ## ######
## ### ## ## ## ### ### ## ## ## ## ## ## ## ### ## ## ##
## #### ## ## ## #### #### ## ## ## ## ## ## ## #### ## ##
###### ## ## ## ## ## ## ### ## ###### ######## ## ## ## ## ## ## ## ## ####
## ## #### ## ## ## ## ## ## ## ######### ## ## ## #### ## ##
## ## ### ## ## ## ## ## ## ## ## ## ## ## ## ### ## ##
######## ## ## ####### ## ## ######## ## ## ## ## ## #### ## ## ######
## ####### ######## ####
## ## ## ## ## ##
## ## ## ## ## ##
## ## ## ## ## ##
## ## ## ## ## ## ##
## ## ## ## ## ## ##
###### ####### ######## ####
Signs seemingly invisible surround us every day. Reading this text would not be possible without them. For instance, we are used to reading text on pages. Pages are often standardized, have a frame-like blank border and text blocks in the middle. Even if it seems natural at first glance, the text in book pages is delimited by its margins, which allows structuring. And websites are often basically just digital book pages. In addition, there are paragraphs, line breaks and indentations that provide structure, indicate pauses or highlight special parts of the text.
These "invisible" structure characters must also be specified in the computer. Example: \n resp. \n\r stands for newline in source code, \t for tab, i.e. indentation. The string: "\n\t This indented sentence breaks\n here and continues on the \tnext line\n" is output as follows:
This indented sentence breaks
here and continues on the next line
From this simple example, you can already see how the unfamiliar indenting and wrapping caused by the special characters in the middle of the sentence changes the flow of reading. It feels wrong and provides at least a moment of attention while reading. The usual reading flow is interrupted. The otherwise invisible characters unfold their effect. It is interesting that they only become perceptible when they disturb. Above all, the characters that are invisible to us and therefore often ignored are the ones that come into focus during hacking.
Many web interfaces on the Internet today are still designed like book pages.
Although text is reduced while images are increased in their use.
Web pages and other digital surfaces, however, are not just about text enriched with images and links.
Under the surface, various processes take place that make the text appear in the desired way on the surface.
We only become aware of these processes when we stumble upon them through interruptions in the familiar design.
When characters appear that disrupt the usual flow of reading...
Err�ors.
So what can the errors that are flushed to the surface reveal about the inner states of the system? What mechanisms and algorithms reveal themselves when something as unexpected and undefined as nothing is to be processed? Hacking would deal with these questions. Art, on the other hand, asks another: What does it do to us as viewers when a system confronts us with errors?
_ _ _
| | ___ __| (_)
_ | |/ _ \ / _` | |
| |_| | (_) | (_| | |
\___/ \___/ \__,_|_|
Joan Heemskerk and Dirk Paesmans, under their pseudonym Jodi, addressed this question in the mid- and late 1990s.
The duo is one of the most important representatives of net.art, which was formed at the same time as the emergence of the World Wide Web.
Many of their works use the aesthetics of technical malfunction as a stylistic device.
Strictly speaking, however, their seemingly senseless hieroglyphic character worlds are not technically a faulty use of the computer.
Because basically there are no specifications about how a computer is to be used.
The idea of which signs are right and which are wrong is based only on conventions developed over time and partly adopted from pre-digital times, like structures from Book pages...
Jodi breaks with these conventions. Tilman Baumgärtel writes that their works often consist of error messages, code snippets, and other cryptic elements of digital culture that literally seem to take on a life of their own on the monitor.
What makes their artistic language interesting in the context of hacking is the attempt to flush the signs from inside the system to the surface, where they disturb us and challenge our notions of digital surfaces. This creates an awareness of the nature of the medium. Digital interfaces are made of code that is displayed graphically. And the code ultimately consists of letters and characters.
_____ __
|_ _| __ __ _ _ __ ___ / _| ___ _ __
| || '__/ _` | '_ \/ __| |_ / _ \ '__|
| || | | (_| | | | \__ \ _| __/ |
_|_||_| \__,_|_| |_|___/_| \___|_| _ _ _
|_ _|_ __ | |_ ___ _ __ _ __ _ _ _ __ | |_ ___ __| | |
| || '_ \| __/ _ \ '__| '__| | | | '_ \| __/ _ \/ _` | |
| || | | | || __/ | | | | |_| | |_) | || __/ (_| |_|
|___|_| |_|\__\___|_| |_| \__,_| .__/ \__\___|\__,_(_)
|_|
On their website wwwwww.jodi.org, it looks at first as if the lower text level of the system has accidentally advanced to the level visible to us on the surface.

screenshot of jodis website
The technical chaos of letters, numbers and control characters with which the computer confronts us in emergencies exceeds anything an artist could come up with in terms of the surreal.
This impression is further enhanced by the color scheme: black background and green font, presumably chosen in reference to the command lines of early computer terminals. Since code normally hides behind surfaces, Jodi's work reverses this process. The mixture of characters now on the surface, at first jumbled and off-putting, invites closer examination. What happened? Why are the signs so jumbled? Is there a hidden order after all, or is this absolute random chaos?
This basically already answers the question of what it does to us when we come across these apparent mistakes.
At first it might scare some of us off, but once the initial shock is overcome, it sparks a curiosity to understand why the mistakes happened.
So Jodi's work invites us to take the first step towards hacking in a very natural way.
The questions of what mechanisms are at work behind it arise on their own, once this curiosity has been awakened.
And the ingenious thing about Jodi's work is that the viewer who has become a hacker is also rewarded for her curiosity with a surprise.
By viewing the source code, you can take a look underneath the surface of a website. Here, many previously hidden clues about the programming and possible further functionalities reveal themselves. The source code of a website is a must-read for a hacker. Surprisingly, the source code presents a completely different picture of the work wwwwww.jodi.org. Under the surface, structures and figures made of letters come to light. A completely different dimension of the characters can be seen.
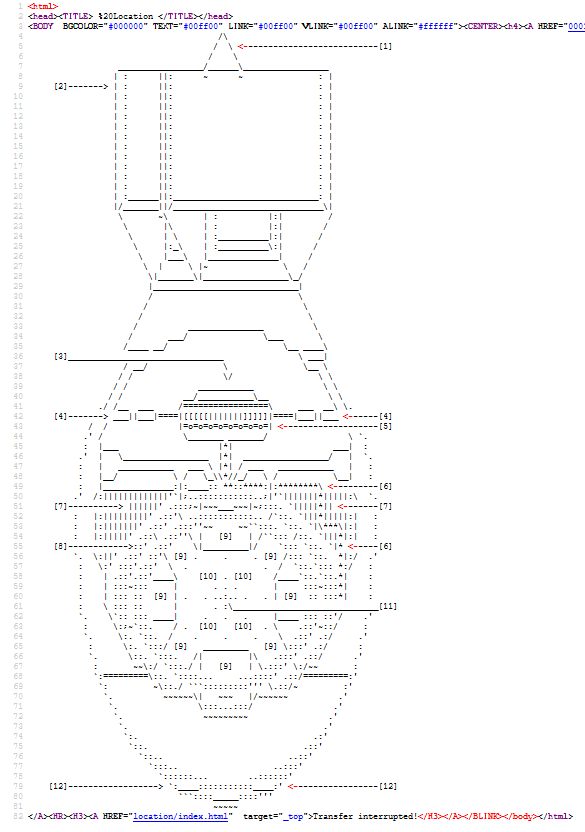
sourcecode from jodis websites
At the top, there are still some HTML code lines, but when scrolling down,
figures reminiscent of construction plans of bombs emerge.
In a direct comparison of the surface and the underlying source code,
it is noticeable that most of the characters are also visible on the surface.
What is missing is their structure.
This makes them look like a computer error or meaningless code hieroglyphs.
If a structure is added by the spaces and line breaks, the seemingly unrelated characters take on a new meaning.
The omission of structural characters allowed Jodi to have an entirely new aesthetic experience
in the perception of web pages and poses questions about habits of using the medium.
__ __ _ ____ _ _
\ \ / /__| |__ / ___|| |_ _ __ _ _ ___| |_ _ _ _ __ ___ ___
\ \ /\ / / _ \ '_ \ \___ \| __| '__| | | |/ __| __| | | | '__/ _ \/ __|
\ V V / __/ |_) | ___) | |_| | | |_| | (__| |_| |_| | | | __/\__ \
\_/\_/ \___|_.__/ |____/ \__|_| \__,_|\___|\__|\__,_|_| \___||___/
The different behavior of the interface and the code can be explained as follows:
In order to display the web page graphically in the sense of the developer or designer,
so-called HTML-tags are used. These tags are used to structure the text.
HTML documents are virtually the basis of the World Wide Web.
The HTML markup language was developed in the early 1990s.
Text in HTML documents is not structured by paragraphs and page breaks, but by the tags responsible for them.
There are semantic and non-semantic tags.
Without these tags, the computer systems do not know the meaning of the words and characters.
A text becomes machine-readable only by them in certain way.
Alexander Galloway describes it this way: The word "Galloway" is meaningless to the machine.
Enriched with the tags <surname>Galloway</surname> it gets a semantic value added.
The machine can now process the word as a last name.
But again, this only works because we know what a last name is.
In the following case, neither we nor the computer know exactly what it is: <art>hacking</art>.
In the source code of wwwwww.jodi.org there are the usual <html> and <body> tags that indicate that it is an HTML document,
but there is nothing that structures the actual content.
The spaces and line breaks in the source text are simply not rendered by the browser on the visible interface,
because it has not been defined how the browser should do that.
For the browser program, the characters that structure texts and book pages for us simply have no meaning.
_________ _________ _________
/ __ \ / __ \ / ______/
/ /_/ | / /_/ | / /____
/ ______/ / __/ / _____/
/ / / /\ \ / /______
/____/ /____/ \___\ /_________/
Interestingly, it would only take a single HTML tag to restore "order" to the interface on all the pages Jodi has created in this style.
A <pre> tag placed in front of the content would tell the browser to actually display the spaces and line breaks...
But Jodi's work is huge and I am interested in the question of what other treasures are hidden on the many crazy pages.
In the following, we will examine the site jodi.org as comprehensively as possible.
Various approaches and tools are used for this purpose.
At the end, a way to explore Jodi's work manually in a simple way is shown.
_____ _ _
| ____|_ __ _ _ _ __ ___ ___ _ __ __ _| |_(_) ___ _ __
| _| | '_ \| | | | '_ ` _ \ / _ \ '__/ _` | __| |/ _ \| '_ \
| |___| | | | |_| | | | | | | __/ | | (_| | |_| | (_) | | | |
|_____|_| |_|\__,_|_| |_| |_|\___|_| \__,_|\__|_|\___/|_| |_|
Jodi.org is considered as a total work of art.
This means that there are not only individual works, but the site as a whole is to be considered an artwork.
Nevertheless, it consists of many small individual parts. And the task now is to find all of them.
Now let's dig deeper into actual web hacking methodology.
A link consists of different parts. At the beginning the protocol is defined with "http://".
Then comes the so-called subdomain.
Then the domain and finally the path to the file that the web server should deliver.
So if jodi.org is the domain, there may be other subdomains. wwwwwww.jodi.org is one of them, for example.
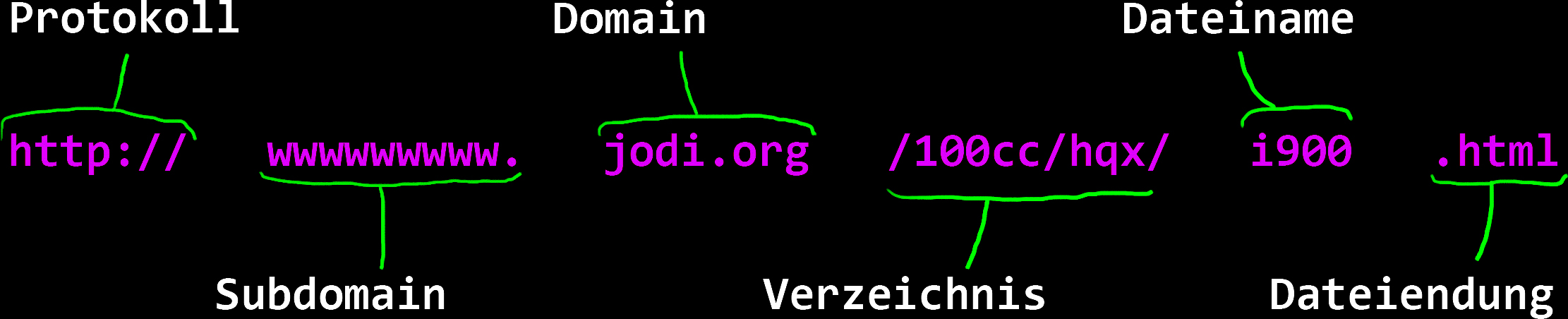
parts of URL
There are a few ways to find the different subdomains. First, it may be helpful to simply Google. Very useful are the so-called google dorks. These are special search queries. In the picture you can see a few dorks, which not only reveal subdomains, but can also be used to search for specific files.
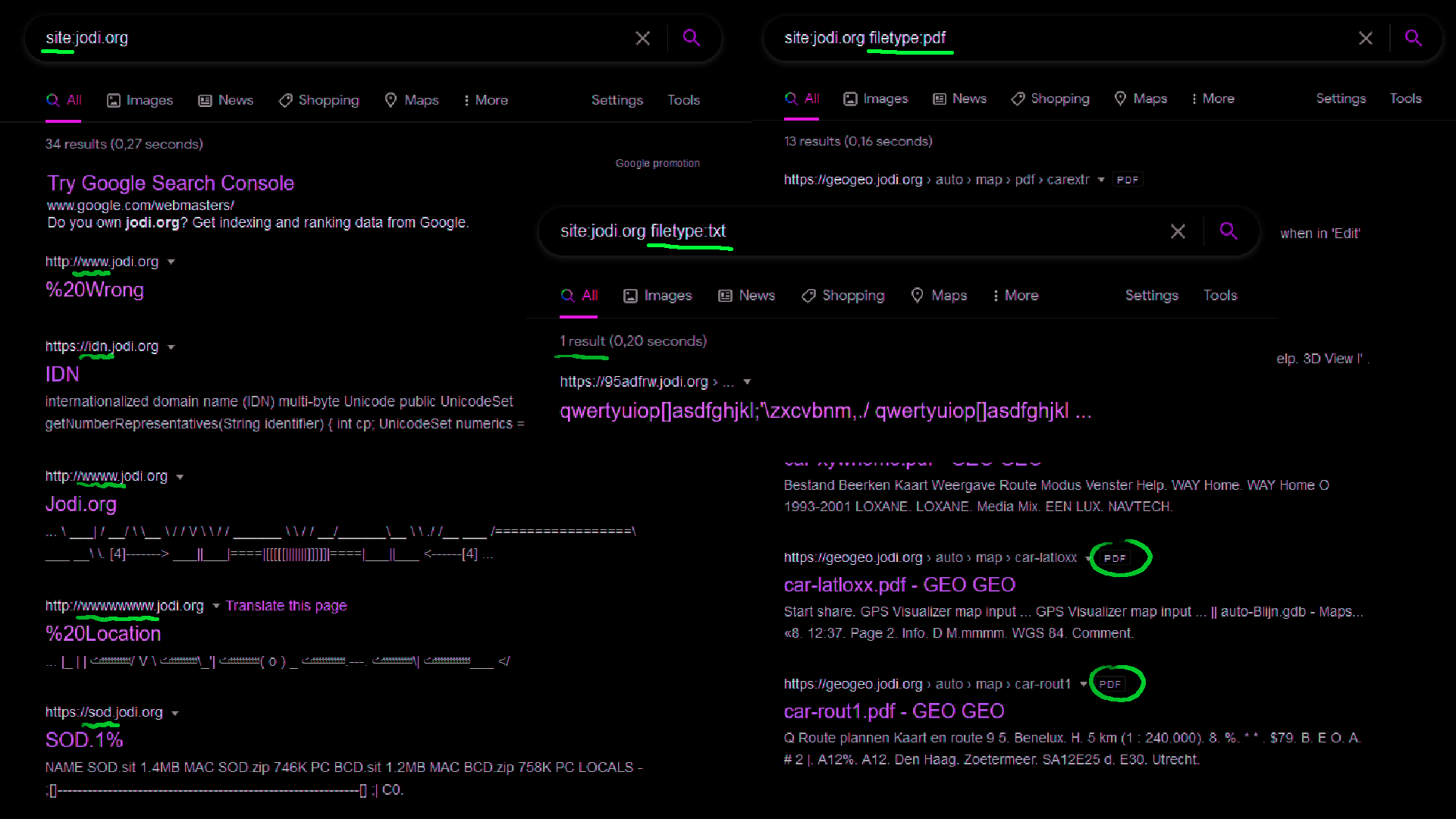
google dorks enumeration
There are also tools on the Internet that specialize in finding out as much information as possible about a domain.
For example Websites like dnsdumpster.com also gives information about the subdomains and more, such as the IP address and information about the services on the web ports.
Another interesting option is the search engine shodan.io.
Here you can search for the IP address and shodan provides information about the location, organization and ports of the server.
The whole process is manually relatively time-consuming and error-prone if there is a lot of information.
Therefore, there are tools that automate this process.
They make automated queries to various online services to find out information about the domain.
The whole thing is called subdomain scraping.
$ amass enum -v -d jodi.org | tee amass.txt
-- snip --
mail.jodi.org
4.jodi.org
lvy.jodi.org
awr.jodi.org
geogeo.jodi.org
ftp.jodi.org
map.jodi.org
www.text.jodi.org
mydesktop.jodi.org
-- snip --
Here you can see the tool amass and next the tool subfinder. Both provide similar results. In total, more than 200 different subdomains come together. But unfortunately, the majority of them are false positives, i.e. detected by the tool, but not usefull in reality.
$ subfinder -all -d jodi.org | tee subfinder.txt
-- snip --
www.95adfrw.jodi.org
44.jodi.org
asdasd.jodi.org
wwwwwwwwwwwwwwww.jodi.org
wwwwwwwwwwwwwwwww.jodi.org
wwwwwwwwwwwwwwwwwww.jodi.org
wwwwww.jodi.org
wwwwwwwwwww.jodi.org
mail.jodi.org
www.oss.jodi.org
admin.jodi.org
-- snip --
The question now is, which of these are still accessible today? To check which domains are reachable there is a tool called eyewhitness, which also takes a screenshot of the pages.
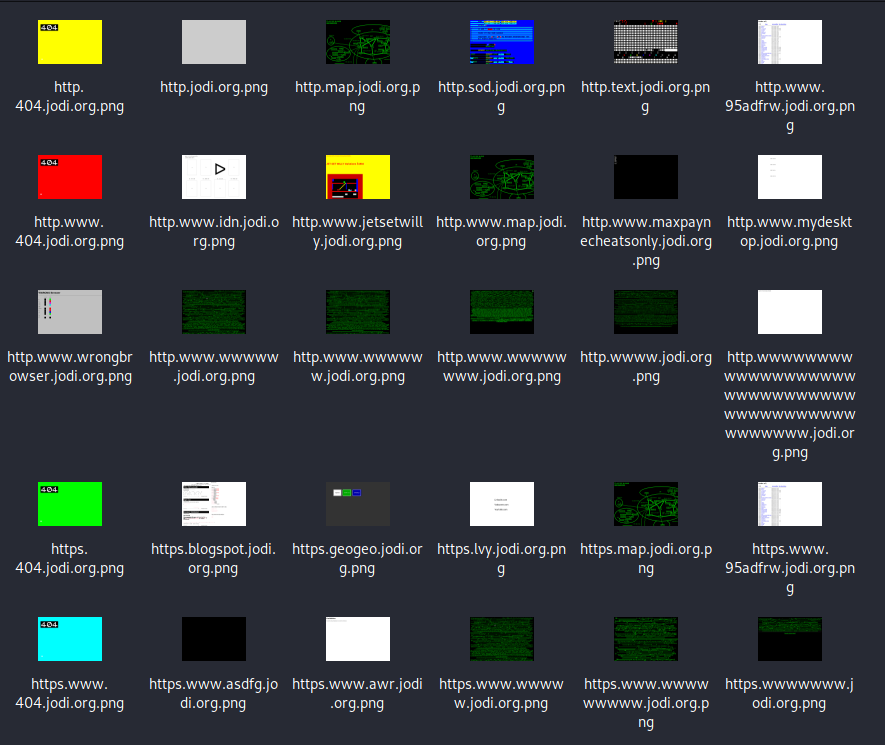
Images from screenshot tool
In the end these are all todays domains returning content:
https://asdfg.jodi.org https://wwwwwww.jodi.org https://www.wwwww.jodi.org https://www.wwwwwwww.jodi.org https://wwwwww.jodi.org https://map.jodi.org https://jodi.org https://404.jodi.org https://wwwwwwwww.jodi.org https://wwww.jodi.org https://geogeo.jodi.org https://text.jodi.org https://blogspot.jodi.org https://idn.jodi.org https://jetsetwilly.jodi.org https://lvy.jodi.org https://maxpaynecheatsonly.jodi.org https://mydesktop.jodi.org https://oss.jodi.org https://sod.jodi.org https://wrongbrowser.jodi.org https://95adfrw.jodi.org https://awr.jodi.org
Many more domains were reachable but returning only one sentence:
Apache is functioning normally
____ _ _
/ ___| _ __ (_) __| | ___ _ __
\___ \| '_ \| |/ _` |/ _ \ '__|
___) | |_) | | (_| | __/ |
|____/| .__/|_|\__,_|\___|_|
|_|
It is strange that just a few of the many domains from the tools remain.
I don't think the scraping-tools found subdomains this specific completely arbitrary.
Therefore I suspect that there were some pages before, that are now offline. (But am not sure)
Fortunately, there is the wayback machine.
This Internet archive makes it possible to retrieve pages that were saved at a certain time in the past.
And that, too, can be automated. This Tool waybackurls makes it possible.
cat all-domains-sorted.txt | ~/tools/waybackurls > waybackurls.txt
It returns a file containing more than 11000 lines.
This means that it gives us back more than just the domains,
it also gives us back real content and documents that was stored in the internet archive at some point.
Again, the urls from the Wayback machine can be checked to see if they still exist today.
You could write a small script for this yourself, which might look something like this:
import requests
with open("waybackurls.sorted.txt", "r") as file:
for line in file.readlines():
r = requests.get(line)
if (r.status_code != 404):
if("Apache is functioning normally" not in r.text):
print(f"{r.status_code}: {line}")
Now we have already collected and reviewed a lot of data.
Nevertheless, things are just getting started.
Because now the entire accessible jodi.org content has to be reviewed.
A technique called spidering is used for this purpose.
The website is called up and checked for links.
These links are then also called and so on.
So it is possible to crawl from one page to the next.
This is also what was exploited in the Webstalker, by the way.
There are a lot of spidering tools but to keep it simple you can just use wget.
This is installed in almost every linux distribution.
A small loop in bash downloads everything from jodi.org:
while read d; do
wget -r -nc -k -l 0 $d
done < domains.txt
# -r = specify recursive download
# -nc = overwrite already existing pages
# -k = make links in downloaded HTML or CSS point to local files
# -l = recursive level (0 for infinitife)
_____ _ ____ _ _ _
|_ _| |__ ___ / ___|| |_ _ __ _ _ ___| |_ _ _ _ __(_)_ __ __ _
| | | '_ \ / _ \ \___ \| __| '__| | | |/ __| __| | | | '__| | '_ \ / _` |
| | | | | | __/ ___) | |_| | | |_| | (__| |_| |_| | | | | | | | (_| |
|_| |_| |_|\___| |____/ \__|_| \__,_|\___|\__|\__,_|_| |_|_| |_|\__, |
|___/
Now that all the files have been downloaded, you can easily navigate through the directories. This way Jodis art immediately gets a completely different structure.
list all of jodis files
Let us now arrange it into different categories. For example display all Images:
scroll all of jodis images
But even more it is about restoring the beautiful ASCII figures. Unfortunately, it was not so easy to pick out the ascii figures relatively quickly. Therefore I came up with the idea to generate an interface. With this you can quickly and easily get an overview of jodi's really amazing work.
____ ___ ____ _ _ _____ ____ ____ _____ ______ _____ ____
| _ \|_ _/ ___| | | |_ _| __ )| _ \ / _ \ \ / / ___|| ____| _ \
| |_) || | | _| |_| | | | | _ \| |_) | | | \ \ /\ / /\___ \| _| | |_) |
| _ < | | |_| | _ | | | | |_) | _ <| |_| |\ V V / ___) | |___| _ <
|_| \_\___\____|_| |_| |_| |____/|_| \_\\___/ \_/\_/ |____/|_____|_| \_\
A small script generates a simple webpage out of all material. It has a good to use menu on the side. This way, Jodi's entire oeuvre can be browsed for digital treasures.
RIGHTBROWSER
Here is the main part of the sourcecode to quick and dirty generate a HTML-Interface...
import os print(""" <html><head><title></title><style> /* cutted this out, you can see it below in sourcecode */ </style></head><body style='background-color: black'> <button class="addpre" onclick="getData()">check source</button> <div class='grid-container'><div class='grid-item'> """) def list_files(startpath): lev = 0 for root, dirs, files in os.walk(startpath): level = root.replace(startpath, '').count(os.sep) indent = '-' * 4 * (level) if(level != 0): if(level < lev): print("</div>"+"</div>"*(lev-level)) elif(level == lev): print("</div>") print(f"<!-- LEVEL {level} -->") print('<button type=\'button\' class=\'collapsible\'>{}{}/</button> <div class=\'content\'> <ul>'.format(indent, os.path.basename(root))) subindent = '-' * 4 * (level + 1) for f in files: p = os.path.join(root, f) print(' <li class="baselink">') print(' <a href="http://{}" target="iframe" onclick="localStorage.setItem(\'url\',\'{}\')">{}</a>'.format(p[2:],p[2:],f)) print(' </li>') print(" </ul>") lev = level list_files(".") print(""" </div></div></div> <div class='grid-item'> <iframe id='iframe' name='iframe' sandbox></iframe> <div id="fakeframe"> <button onclick="closeframe();">close</button> <div id="fakeframecontent"> </div></div></div></div> <script> /* cutted this out, you can see it below in sourcecode */ </script></body></html> """)
You can try out the RIGHTBROWSER below: